Considerations on using Neo4j for persisting the class cache structure
Ivan Senic tried to create a small POC for using the Neo4j in order to store the information about loaded classes and their relationships on disk. The Neo4j being the graph database, seamed as the perfect candidate for storing the information we extract from the byte code.
Considered Approaches
Several set-ups were tested in order to speed up the development of the POC. The general idea was to use some kind of ORM mapping to ease up saving of already existing class cache entities to Neo4j. As well we strongly favored the embedded Neo4j option as then the user will not have to start additional neo4j process in order to run the CMR.
Spring Data Neo4j
First try was to set up the Spring support for the Neo4j. The general information on this can be found here: http://projects.spring.io/spring-data-neo4j/
The Spring-Neo4j product has two version lines basically. One is the line 3.x and newer line is 4.x. (we wanted logically to start the newest possible line). Problem with the version 4.x is that there is no embedded DB support for now, but they are based on the neo4j-ogm project that should be better option in general for accessing the database. Problem with both version lines is that they require Spring 4 to be used (3.x requires Spring 4.0.7, 4.x requires Spring 4.2.3). Our CMR currently still uses version 3.x of Spring, thus we were blocked here by not being able to set-up all the needed dependencies. The decision was to try something else as we did not want to invest time in Spring version update at the moment.
Neo4j-OGM
The Neo4-OGM is an own Neo4j project for mapping objects to the graph. It's basically what Spring project in version 4.x is based on. For example, all the annotations are actually belonging to the neo4j-ogm project, thus Spring is just defining an additional data access layer on top. This seamed as the something worth of trying. However, the neo4j-ogm is (at the moment version 1.1.3) also lacking the support for the embedded database. After contacting their team they were confident that the support that comes with version 2.0 will be released by the end of 2015 (see conversation here). They also assured that significant API changes will be performed, so switching from implementation using remote Neo4j to using embedded would be thing of beans configuration. Because of all this decision was made to try making the POC with the remote database using neo4j-ogm, as anyway the support for embedded is on the way.
Proof of Concepts with Neo4j-OGM
Dependencies
This is the list of the dependencies our CMR would need to add in order to use neo4j-ogm in remote mode (note that at least the httpclient dependency will be gone with the embedded mode):
Entities
The idea was to enrich already existing entities with the OGM annotations and use them directly with OGM session for saving, loading, etc. Here there are few adaptations we needed to do:
- We needed to create a Neo4jEntity class that will introduce the Long id field, as this is necessary when saving to the neo4j. This will be used as node id in the graph.
- We have a lot of bi-directional relationships, ex. Class implements set of Interfaces, but Interface also has a set of realizing Classes. It seams that this is not how the entities should be connected in graph database. In fact since you can navigate from any side of the relationship, in our case it's enough to have one relationship type to connect two nodes (more on this http://graphaware.com/neo4j/2013/10/11/neo4j-bidirectional-relationships.html). Thus for the POC half of the relationships are made transient, thus neo4j would only have relationships in one direction. But if we decide to go this way, we would need to refactor our model and have only one-to-many relationships. It's still unclear how would this relate to other functions using our model.
Run n' Gun
The initial goal for POC was to be able to save classes information to the database as they are sent from the agent. To achieve this two new versions of IClassCacheModification and IClassCacheLookup interfaces are made that would work with OGM session to persist data in Neo4j and update the data as well when new classes are loaded. The approach was same as before, all not-initialized classes are also saved in the Neo4j, so that all relationships are preserved.
The two new interface were hooked into the existing class cache and the initial tests were run with the agent on Calculator (app. 1000 loaded classes). From functional point of view everything was perfect, it seams like all the entities are saved correctly in the database, with correct relationships, properties, etc. However, the performance of processing one loaded type structure was terrible. Almost half dozen of the requests from the Agent were hitting the 3 seconds time-out. Checking with the JVisualVM showed that actually memory usage on the Neo4j server was extreme and rises in terms of seconds. I also hit few OOM exceptions as well.
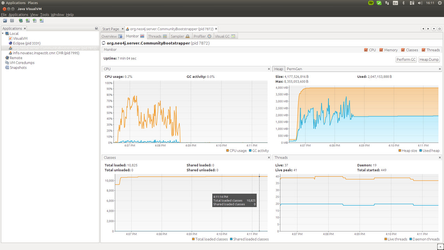
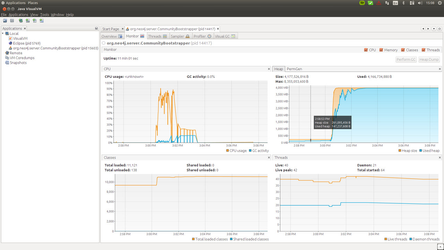
Operations & Troubleshooting
I contacted the Neo4j-OGM team on Google groups and presented them the problems I am facing (conversation https://groups.google.com/forum/#!topic/neo4j/Q-rvbYha4-M). I also instrumented the CMR with inspectIT (storage attached, v1.6.4.69) and tried to capture all the timings and queries set to the remote server in order to do my own investigation. From the answers on the Google groups and my own diagnoses I came up with following problems and possible solutions:
Save operations
The OGM were quite aware of the saving problems there might be. They immediately told me to use 1.1.4-SNAPSHOT and to try to first save all nodes and then save relationships between them. So I tried to do so, but I am not sure how much is this actually usable as I was again seeing some crazy queries when trying to finally save new relationships. As well I was seeing high times in executing the saving of nodes without relationships.
Saving of node properties without relationships
The main problem here is the time of execution. And I can not figure if this is due to the remote database access or is this the general times (highly doubt) of the Neoj4 when saving. Anyway saving one node costs at least 10ms. If you have a look on the following invocation sequence, you can see that most of the time there is lost in saving all the method nodes of a class/interface. So we are linearly increasing the request time based on the numbers of methods we need to save. In my opinion this must be purely related to the server round-trip needed for each request and I am sure it must be faster with embedded approach (as the query they are sending looks totally OK). They suggested me to use save with the collection of entities which I was happy to use for methods, but this also executes a HTTP call per object trying to save.
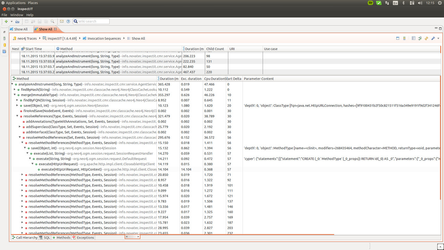
Saving of relationships
As the final step of the merge operation I am trying to save all the relationships (save with depth 1). Here I think the problem with the memory occurs as sometimes really strange queries are produced:
| Correct | In-correct |
|---|---|
They say that these crazy queries are occurring when not all nodes are saved before saving relationships. I will additionally check if this is true. Their comment on this was: "The one you see in exampleDepth1Query is the not-so-optimal query and it's being used because what you're saving does not satisfy the conditions of only new relationships (no new nodes, no updated nodes, no relationship updates, no relationship entities). Unfortunately this means that the optimisation applies to one operation only and that is "create relationships when the nodes on either end are persisted". As I mentioned earlier, work is underway to optimise all the queries and then you should not have to worry about the manner in which you save entities.".
Loading operations
A problem for us is also time needed to load some node from the database to check if the same one (FQN/hash) already exists. Also here the times are around 10ms per node and I don't get why. I even set the index on the fqn property that creates really fast execution plan for the query, but still the times did not improve. I see two possibilities here:
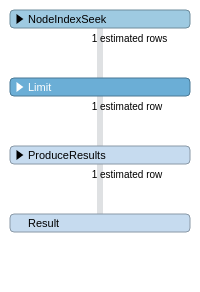{kind=link}
- It's the server round trip thing
- It's related that OGM specifies "resultDataContent" : "graph" which returns the node with it complete reachable graph. I asked them how can this be changed to just one row and I still did not get any answer. I also think that the solution here might be to load data by the entity id (because then you can specify depth of the graph), but for this we need to internally map the FQNs/hashes to the Ids.
Further steps
It's hard to define what should be our further steps. Seams like introducing Neo4j is not as easy as it sounds, with respect that OGM is not so mature. This especially relates to the saving as no bulk saving is possible in the moment.
I also see the problem with not being able to test everything with the embedded database as I would expect everything to be faster.
Still I believe that this should be our goal, although we need to invest a lot of time to align everything to having data in Neo4j (we just test saving/updating of structure for now, but what about all the other things, like checking what should be instrumented, etc). Also we need to come to some kind of better design, see how we wanna deal with situations when we have more agents (do we go database per agent or we include agent information in structure).
As we have the working class cache thingy in memory I would advise to continue working on the memory-based implementation at least until the version 2.0 of neo4j-ogm is officially released. As Stefan Siegl said memory should not be a problem these days, so we can clearly say if you run CMR make sure you give it enough RAM as we will store complete class cache structure in memory.